What are canonicalisation attacks?
Unauthorised access of file and directories on the web server machine by tampering file/directory paths that a web site normally allows users to enter as part of its functionality. The attack is typically carried out by entering the path of the file in input field on a web page or by supplying it as part of the URL.
What are the consequences?
Loss of confidentiality, integrity and a denial of service results if files are deleted.
What files can the attacker access?
Any file or folder on the disk(s) of the web server m/c.
Defending applications against canonicalisation attacks
- Administrative Controls
a) Ensure that the web server hosts on a secure file system like NTFS.
b) Set ACL (access control lists) on files and folders. This can be done by setting appropriate permissions in the [Security] tab in the [Properties] tabpage of files and folders. Ensure that only administrators can access sensitive files and folders.
c) Do not keep sensitive files, source code or any such material on the web server machine.
d) Turn-off MS-DOS file name (8.3) convention on the machine by adding the following setting to the HKEY_LOCAL_MACHINE \SYSTEM \CurrentControlSet \Control \FileSystem registry key: NtfsDisable8dot3NameCreation : REG_DWORD : 1.
Note that this option does not remove previously generated 8.3 filenames.
- Programming Controls
a) White-list directories that you would like to have your application access rather than black-list them.
BAD WAY:
string InputFilePath = GetPathFromUser();
if ( InputFilePath = = "Secret Directory")
Output ("Access Denied")
CORRECT WAY
string InputFilePath = GetPathFromUser();
if ( InputFilePath startsWith "Application-accessible Directory")
allow Further operations...
else
Output ("Access Denied")
b) If ACLs have been set (Point b in Administrative Controls, above) then turn on Integrated Windows Authentication (in IIS) and impersonate using the WindowsIdentity class in your .NET code.
c) Filter the user input path by subjecting it to MapPath in .NET. MapPath( ), according to MSDN, maps the virtual path in the requested URL to a physical path on the server . To prevent the path from mapping to a path in another application on the same server, set MapPath's third parameter to false.
d) Use regular expressions to control the file\folders that can be accessed. This can be implemented in a) above.
e) Reduce UTF-8 to its canonical form. UTF-8 text can be represented in multiple forms - guard against this.
Thursday, August 31, 2006
Wednesday, August 30, 2006
HTTP Fingerprinting
What is HTTP Fingerprinting?
HTTP Fingerprinting is a technique that helps determine the following:
a) The web server software hosting the website
b) Version and other deployment details of the webserver
How does HTTP Fingerprinting help?
Depends on which side you are looking from. From a bonafide perspective, HTTP fingerprinting allows n/w administrators to profile the webservers in their environment and monitor patches. It also allows an pen-tester/security auditor to narrow down the list of attacks that the server must be subject to expose vulnerabilities.
Why is HTTP Fingerprinting possible?
Try this. Ask a programmer to implement a string comparison function. Provide the flowchart that details the logic. Now ask another programmer to do the same. Provide the same flowchart to this programmer too. You can be sure that the implementations, although accurate, would be dissimilar. The same goes for the way in which HTTP web servers are implemented. There are several vendors in the market today viz. Microsoft, Apache, Netscape and the list goes on. The web server implementations from each of these vendors have their own nuances and subtleties in which they implement the HTTP protocol. This, unfortunately, is the reason why HTTP Fingerprinting becomes possible!
How does one go about HTTP fingerprinting?
- Use banner grabbing
Try the following,
(i) run telnet IP_Address 80 at the command prompt. Substitute IP_Address with the IP address of the machine hosting the web server.
(ii) Type in the telnet window HEAD / HTTP/1.0
(iii) Press Enter.
(iv) Press Enter again.
If all runs fine, what you should see is the web server banner! Feast on the information that you will see. You should be able to determine the following:
- The default home page configured for the site
- The last time the page was modified
- The web server running along with its version
- The time on the server
...and lots more.
Banner grabbing allows an attacker to get vital information about the web server software running on the box. It allows script kiddies (and determined hackers) to narrow down to the Achille's heel of the website. The other things you can do is best left to your imagination!
- Difference in HTTP implementations
This involves subjecting the web server to different HTTP messages and observing the responses. These responses are then compared to expected responses from the corresponding web servers. Matches will indicate a correct recognition of the web server.
Illustrating this point, Microsoft IIS 6.0 when subject to a HEAD / HTTP/1.0 emits out a response in which Server and Date are contiguous. The same is not seen for other web servers. More examples can be found at http://net-square.com/httprint/httprint_paper.html
How does one prevent HTTP fingerprinting?
- By changing the HTTP server banner string to something obscure or misleading
- Transposing the HTTP headers so as to remove any points of distinction
- Using custom HTTP error codes such as 404 or 500
- Using HTTP server plug-ins available that allow you to do some of the above
HTTP Fingerprinting Bottomline
HTTP fingerprinting remains the "entry-point" for a user (whatever his/her intentions) and offers him/her a clear line-of-sight perspective. HTTP fingerprinting also remains a necessary evil.
HTTP Fingerprinting is a technique that helps determine the following:
a) The web server software hosting the website
b) Version and other deployment details of the webserver
How does HTTP Fingerprinting help?
Depends on which side you are looking from. From a bonafide perspective, HTTP fingerprinting allows n/w administrators to profile the webservers in their environment and monitor patches. It also allows an pen-tester/security auditor to narrow down the list of attacks that the server must be subject to expose vulnerabilities.
Why is HTTP Fingerprinting possible?
Try this. Ask a programmer to implement a string comparison function. Provide the flowchart that details the logic. Now ask another programmer to do the same. Provide the same flowchart to this programmer too. You can be sure that the implementations, although accurate, would be dissimilar. The same goes for the way in which HTTP web servers are implemented. There are several vendors in the market today viz. Microsoft, Apache, Netscape and the list goes on. The web server implementations from each of these vendors have their own nuances and subtleties in which they implement the HTTP protocol. This, unfortunately, is the reason why HTTP Fingerprinting becomes possible!
How does one go about HTTP fingerprinting?
- Use banner grabbing
Try the following,
(i) run telnet IP_Address 80 at the command prompt. Substitute IP_Address with the IP address of the machine hosting the web server.
(ii) Type in the telnet window HEAD / HTTP/1.0
(iii) Press Enter.
(iv) Press Enter again.
If all runs fine, what you should see is the web server banner! Feast on the information that you will see. You should be able to determine the following:
- The default home page configured for the site
- The last time the page was modified
- The web server running along with its version
- The time on the server
...and lots more.
Banner grabbing allows an attacker to get vital information about the web server software running on the box. It allows script kiddies (and determined hackers) to narrow down to the Achille's heel of the website. The other things you can do is best left to your imagination!
- Difference in HTTP implementations
This involves subjecting the web server to different HTTP messages and observing the responses. These responses are then compared to expected responses from the corresponding web servers. Matches will indicate a correct recognition of the web server.
Illustrating this point, Microsoft IIS 6.0 when subject to a HEAD / HTTP/1.0 emits out a response in which Server and Date are contiguous. The same is not seen for other web servers. More examples can be found at http://net-square.com/httprint/httprint_paper.html
How does one prevent HTTP fingerprinting?
- By changing the HTTP server banner string to something obscure or misleading
- Transposing the HTTP headers so as to remove any points of distinction
- Using custom HTTP error codes such as 404 or 500
- Using HTTP server plug-ins available that allow you to do some of the above
HTTP Fingerprinting Bottomline
HTTP fingerprinting remains the "entry-point" for a user (whatever his/her intentions) and offers him/her a clear line-of-sight perspective. HTTP fingerprinting also remains a necessary evil.
Wednesday, August 16, 2006
Encryption considerations in software applications
Encryption is the new buzzword that is often recommended as the panacea for most security ills. I do not disagree, however, there are a few caveats that you need to consider before using encryption:
1. How will the encryption keys be generated?
A primary requirement when generating cryptographic keys is that they should be random or unpredictable. Unfortunately, the problem with generating random numbers is that you have to supply a sufficiently random number as seed in the first place - a classical chicken and the egg situation. Having said this, however several techniques (to be covered in a future post) exist to generate random numbers.
2. What encryption technique will your application use?
First things first. Hashing, message digesting and digital signatures DO NOT constitute encryption. Encryption means garbling of data with the help of a secret "encryption key" and ungarbling it using a secret (of course) "decryption key".
When encryption key == decryption key, this is called Symmetric Key encryption.
When encryption key != decryption key, this is called Asymmetric Key (or Public Key) encryption.
You need to decide first whether your application will use symmetric or asymmetric key encryption. Each of these have their +/- but you need to decide which one to use. [Note: When you use asymmetric key encryption, you often end up using symmetric key but that's another story]
3. What encryption algorithm will you use for encryption?
Algorithms are nothing but the sequence of steps to be carried out when encrypting data and decrypting (usually the reverse) previously encrypted data. Enough has been written about not using home-grown encryption algorithms, so lets assume that you are planning to use a standard and tested algorithm. Here's what I recommend -
Symmetric key encryption - Use AES (Rijndael - pronounced "Rhine doll")
Aysmmetric key encryption - Use ECC, else use the prolific RSA algorithm.
4. What are the recommended key sizes to be used?
This is a function of the application's security requirements. If you are protecting low-worth data you can can settle for smaller key sizes than when protecting high-worth data. But there are two important points to remember:
1. How will the encryption keys be generated?
A primary requirement when generating cryptographic keys is that they should be random or unpredictable. Unfortunately, the problem with generating random numbers is that you have to supply a sufficiently random number as seed in the first place - a classical chicken and the egg situation. Having said this, however several techniques (to be covered in a future post) exist to generate random numbers.
2. What encryption technique will your application use?
First things first. Hashing, message digesting and digital signatures DO NOT constitute encryption. Encryption means garbling of data with the help of a secret "encryption key" and ungarbling it using a secret (of course) "decryption key".
When encryption key == decryption key, this is called Symmetric Key encryption.
When encryption key != decryption key, this is called Asymmetric Key (or Public Key) encryption.
You need to decide first whether your application will use symmetric or asymmetric key encryption. Each of these have their +/- but you need to decide which one to use. [Note: When you use asymmetric key encryption, you often end up using symmetric key but that's another story]
3. What encryption algorithm will you use for encryption?
Algorithms are nothing but the sequence of steps to be carried out when encrypting data and decrypting (usually the reverse) previously encrypted data. Enough has been written about not using home-grown encryption algorithms, so lets assume that you are planning to use a standard and tested algorithm. Here's what I recommend -
Symmetric key encryption - Use AES (Rijndael - pronounced "Rhine doll")
Aysmmetric key encryption - Use ECC, else use the prolific RSA algorithm.
4. What are the recommended key sizes to be used?
This is a function of the application's security requirements. If you are protecting low-worth data you can can settle for smaller key sizes than when protecting high-worth data. But there are two important points to remember:
- Key sizes for symmetric and asymmetric algorithms vary greatly from each other.
- When using a both symmetric and asymmetric algorithms, ensure that the crack resistivity provided by the combination is equivalent or higher than that required by the application.
What is a security pattern?
Security patterns are nothing but established ways of implementing security features in applications. Lets try and understand why we need security patterns. More than often, developers are confronted with a situation in which only the application features to be implemented are given to them, leaving them with the onerous task of implementing those features. Now there is nothing wrong with that, except that security of the feature take a back seat. Lets take a simple example. Say, you have been asked to develop a user login module. This module accepts a user name and password from the user and authenticates the user against the password stored in database. When the developer begins to code this feature he will naturally focus only on the functionality and the means to the end. He will care little (and it is not in his interest to) about the security best practices to be followed, both in design and coding. Clearly something is missing. Consider the following. What if...
the developer had a pre-existing security design that he could use for implementing a feature? A design that was resilient to the possible attacks on his module and that incorporated globally-accepted best practices.
he was not required to worry about the "hows", "whys" and "whats" of security for that feature?
Security patterns come in and fulfil that need. [Btw, this blog contains several such security patterns and best practices that you can use to develop more secure applications. Have fun.]
the developer had a pre-existing security design that he could use for implementing a feature? A design that was resilient to the possible attacks on his module and that incorporated globally-accepted best practices.
he was not required to worry about the "hows", "whys" and "whats" of security for that feature?
Security patterns come in and fulfil that need. [Btw, this blog contains several such security patterns and best practices that you can use to develop more secure applications. Have fun.]
Friday, August 11, 2006
Application Database Security

In this post, I shall discuss the significance of database security and the security gotchas to consider. [I shall discuss the steps to take to mitigate these security risks in a separate post.]
Refer to the figure above. Note the following when viewing the figure:
a) The lower two machines viz. the bonafide client and the bonafide server represent the trustworthy systems.
b) The upper two machines represent bogus machines either physically or logically placed in your application environment.
c) Security considerations appear in red circles with numbers in them. viz. 1 through 6.
Security Considerations
(1) Database client subversion
(2) Database client impersonation (masquerade)
(3) Database server subversion
(4) Database server impersonation (masquerade)
(5) Vulnerabilities related to data flowing between the client and the server
(6) Vulnerabilities related to data stored on the database server
Thursday, August 10, 2006
AppSec Best Practice#1 - User Account Lockouts
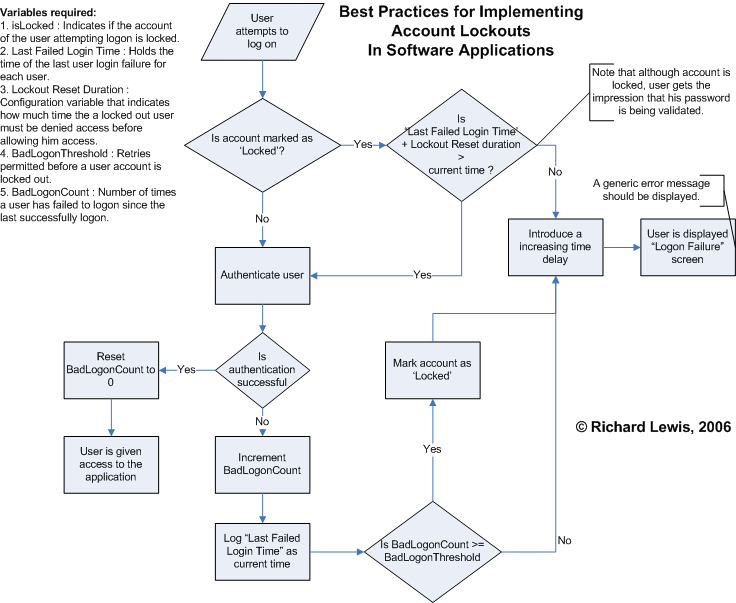
User account lockouts should be designed with caution. Take a look at what you must do - a programmers perspective. Note that this is agnostic of application types viz. web, desktop etc.
Single Sign-On (SSO) and SAML (Security Assertion Markup Language)
What is SSO?
Single Sign-On (SSO) requires a user to authenticate himself to a service one time and does not require reauthentication for other services of the system linked by the SSO framework.
SAML is yet another acronym for you to remember. It stands for Security Assertion Markup Language. The ‘ML’ in the name gives away that SAML is XML based.
Here’s the single important reason why applications need SAML – SAML allows seamless inter-domain sharing of security information. This was not easy before SAML was created.
Thumb-rule for determining if my application requires SAML
This answer is answered by asking this simple question:
Does your application, either currently or in the near future, have a business need for offering a seamless user experience of service usage across business partners and other 3rd party service providers?
If the answer to the above question is ‘Yes’, your application needs SAML
Some advantages afforded by SAML?
1. Platform neutrality
SAML abstracts the security framework away from platform architectures and particular vendor implementations. This makes security more independent of application logic which is an important tenet of Service-Oriented Architecture.
2. Loose coupling of directories/databases
SAML does not require user information to be maintained and synchronized between directories/databases.
3. Improved online experience for end users
SAML enables single sign-on by allowing users to authenticate at an identity provider and then access service providers without additional authentication. In addition, identity federation (linking of multiple identities) with SAML allows for a better-customized user experience at each service while promoting privacy.
4. Reduced administrative costs for service providers
Using SAML to "reuse" a single act of authentication (such as logging in with a username and password) multiple times across multiple services can reduce the cost of maintaining account information. This burden is transferred to the identity provider.
5. Risk transference
SAML can act to push responsibility for proper management of identities to the identity provider, which is more often compatible with its business model.
Single Sign-On (SSO) requires a user to authenticate himself to a service one time and does not require reauthentication for other services of the system linked by the SSO framework.
SSO addresses a common issue – that of requiring users to manage and remember authentication credentials (usually a username/password pair) for every service or application they have been subscribed to.
SSO requires that users need remember only one set of authentication credentials. This set of authentication credentials is “passed-on” to other SSO-enabled services (or applications) so that the user can use them transparently without having to reauthenticate.

How is SSO typically implemented
You can implement SSO using your own bespoke SSO logic implementation or you can use a standards-based technique. Either option has it’s own advantages and disadvantages.
Advantages of bespoke programming means that you have a lot of versatility and you are in the driver’s seat when deciding the level of SSO you are looking at. There are disadvantages too, however. Chief among them are reliance on in-house expertise (which is often not available or insufficient) and lack of scalability, extensibility and performance.
On the other hand if you adopt standards-based techniques you are assured of an industry-accepted solution which augurs well for the reliability, scalability, extensibility and performance of the application. Disadvantages, typically, are associated with implementation teams having to learn “another new” standard and code to the specification, although one may counter-argue that implementations may already exist in the market.
Techniques used for SSO
Proxy-based SSO and SAML-based SSO are two most common techniques used for SSL implementation. This article does not go into the details of proxy-based SSO.
SAML is yet another acronym for you to remember. It stands for Security Assertion Markup Language. The ‘ML’ in the name gives away that SAML is XML based.
Here’s the single important reason why applications need SAML – SAML allows seamless inter-domain sharing of security information. This was not easy before SAML was created.
Thumb-rule for determining if my application requires SAML
This answer is answered by asking this simple question:
Does your application, either currently or in the near future, have a business need for offering a seamless user experience of service usage across business partners and other 3rd party service providers?
If the answer to the above question is ‘Yes’, your application needs SAML
Some advantages afforded by SAML?
1. Platform neutrality
SAML abstracts the security framework away from platform architectures and particular vendor implementations. This makes security more independent of application logic which is an important tenet of Service-Oriented Architecture.
2. Loose coupling of directories/databases
SAML does not require user information to be maintained and synchronized between directories/databases.
3. Improved online experience for end users
SAML enables single sign-on by allowing users to authenticate at an identity provider and then access service providers without additional authentication. In addition, identity federation (linking of multiple identities) with SAML allows for a better-customized user experience at each service while promoting privacy.
4. Reduced administrative costs for service providers
Using SAML to "reuse" a single act of authentication (such as logging in with a username and password) multiple times across multiple services can reduce the cost of maintaining account information. This burden is transferred to the identity provider.
5. Risk transference
SAML can act to push responsibility for proper management of identities to the identity provider, which is more often compatible with its business model.
OWASP, Mumbai Chapter - 2nd Meet - 31-July -06
I spoke on the Significance of Random Numbers in Application Security. I started off with the practical usage of random numbers. I explained how good random number generation prevents applications from malfunctioning, increases strength of cryptographic operations which in turn increases entropy associated with the key.
I went on to explain how random numbers automate otherwise manual tasks and how it increases the security of application. Explaining the concepts of entropy and seeds I explained the level it should be reached in an application. Finally, I spoke about the various sources of random numbers.I also showed developers the simple mathematics required to calculate minimum password lengths, given the security requirements.
You can find my presentation here.
I went on to explain how random numbers automate otherwise manual tasks and how it increases the security of application. Explaining the concepts of entropy and seeds I explained the level it should be reached in an application. Finally, I spoke about the various sources of random numbers.I also showed developers the simple mathematics required to calculate minimum password lengths, given the security requirements.
You can find my presentation here.
OWASP, Mumbai Chapter - 1st Meet - 24-June-06
I presented on Secure Coding Fundamentals and elucidated the Cost factor inculcated due to insecure code resulting in Network Cost, Productivity Cost and so on. Further explaining the basic reasons of threat to code, I explained how the mistakes done by the Programmers, I/O, API Abuse, Environment & Configuration and Time & State were responsible for Security flaws in an application. Moving ahead, I laid down a few principles to be followed as Secure Coding – General Guidelines for all the languages and specific Secure Coding Guidelines for C & C++, Java and .NET
You can get my presentation here.Memory Allocation Best Practices in C and C++
Introduction
Tomes (and I'm talking of real big tomes) are available on secure coding in C and C++. They describe the details of the language, why C,C++ are so insecure and coding patterns and anti-patterns. They tell you what to chew and what to eschew. At the end of it all - when you come down to writing code - how many of these best practices do you remember?
The answer to the above questions is best left to your judgement. In this secure programming series, I intend to bring before you collections of programming best practices collected from the following sources:
1. My own experience and the invaluable experience that I have obtained when reviewing source code.
2. Numerous books available on the topic (my favourite being Secure Programming in C and C++ by Robert Seacord). I recently picked up Exceptional C++ and More Exceptional C++ by Herb Sutter and wonder how I did without these ones!
This article gives you tips to follow when allocating and deallocating memory in C and C++. If your code does not follow them, then you run a risk of making your programs susceptible to all types of attacks (describing the attacks does not fall in the scope of the article)
Without wasting any more of your time (or mine) let us dig in.
Secure Memory Allocation Tips Common to C and C++
Tip 1 - Use static buffers wherever possible. The compiler automatically frees such memory.
Tip 2 - Previously allocated memory should be manually freed, after it is no longer required.
Dont laugh, meet someone who's making a switch from Java into C,C++ and you'll know what I'm talking about.
Tip 3 - Given an option to choose between calloc/malloc or new to allocate memory, go in for the latter - use new, dont use calloc/malloc.
Tip 4 - When using C and C++ code together, if new has been used to allocate memory, use delete to free it. Do not use free. Likewise, if malloc or calloc has been used to allocate memory, use free when deallocating. Do not use delete.
Unfortunately, many programmers feel they can get away with using free when allocation has been done by new (and vice versa) because they discovered while debugging that new was implemented using malloc and that delete was implemented using free! Don't fall in this trap.
Tip 5 - Often a function requires to set a buffer supplied by the caller. The length of the buffer may be unknown to the caller so the caller may not know how much memory to allocate before supplying that buffer to the function. In such cases the function should provide a means for the caller to determine how many bytes are required to be allocated.
A common way to do this is by allowing the caller to call the function with a special argument so that it will return the number of bytes the caller must allocate for the buffer.
Tip 6 - When shipping code libraries (or SDKs as they are called) provide wrapper functions that encapsulate new and delete. This helps prevent single-threaded and multi-threaded runtime issues.
Tip 7 - Use unsigned integer types to hold the number of bytes to be allocated, when allocating memory dynamically. This weeds out negative numbers. Also check the length of memory allocated against a maximum value.
Tip 8 - Do not allocate and deallocate memory in a loop as this may slow down the program and may sometime cause security malfunctions.
Tip 9 - Assign NULL to a pointer after freeing (or deleting) it. This prevents the program from crashing should the pointer be accidentally freed again. Calling free or delete on NULL pointers is guaranteed not to cause a problem.
Tip 10 - Compilers are known to vaporise calls to memset() that appear after all modifications to the memory location is complete for that flow. Use SecureZeroMemory() to prevent this from happening.
Tip 11 - When storing secrets such as passwords in memory, overwrite them with random data before deleting them. Need to note that free and delete merely make previously allocated memory unavailable, they dont really 'delete' data contained in that memory.
Tip 12 - An easy way to find out if your code is leaking memory is by executing it and examining its memory usage either using Task Manager on Windows or top on Linux.
Secure Memory Allocation Tips in C
Tip 1 - Ensure that 0 (zero) bytes are not allocated using malloc According to the documentation, behaviour for malloc( ) for this case is undefined.
Tip 2 - Always check the pointer to the memory returned by calloc/malloc. If this pointer turn out to be NULL, the memory allocation should be considered unsuccessful and no operations should be performed using that pointer.
Tip 3 - When allocating an array of objects, remember to free the array in a loop.
Tip 4 - Do not use realloc when allocating buffers that will store sensitive data in them. The implementation of realloc copies and moves around the data based on your reallocations. This implies that your sensitive data ends up in several other areas in memory which you would have no means of "scrubbing".
Secure Memory Allocation Tips in C++
Tip 1 - When allocating collections use
std::vector
rather than
thing* pt = new thing[100];
The vector defined above is clearly defined on the stack and therefore memory deallocation will be handled by the compiler. If the storage needs a longer lifetime, say as part of a larger class instance, then make it a member variable and initialize the storage with assign() when required.
Tip 2- When using new to allocate an array of objects, use the delete [ ] convention when freeing memory. Using delete without the subscript operator [ ] will result in a memory leak.
Tip 3 - Use auto_ptr more often than you currently do when allocating so that deallocation is handled automatically. Remember the following guidelines when dealing with auto_ptrs.
- An existing non-const auto_ptr can be reassigned to own a different object by using its reset() function.
- The auto_ptr::reset() function deletes the existing owned object before owning the new one.
- Only one auto_ptr can own an object. So after one auto_ptr (say, P1) has been assigned to another auto_ptr (say, P2) do not use P1 any longer to call a method on the object as P1 is reset to NULL. Remember that the copy of an auto_ptr is not equivalent to the original.
- Do not put auto_ptrs into standard containers. This is because doing this creates a copy of the auto_ptr and as mentioned above the copy of an auto_ptr is not equivalent to the original.
- Dereferencing an auto_ptr is the only allowed operation on a const auto_ptr.
- auto_ptr cannot be used to manage arrays.
Tip 4 - When using new enclose it within a try-catch block. The new operator throws an exception and does not return a value. To force the new operator to return a value use the nothrow qualifie as shown below:
thing * pt = new (std::nothrow) thing[100];
Finally...
I hope you enjoyed reading these tips. If you did, please vote and rate this article below. I shall wait for your comments and feedback. I will collate comments from all of you and update the article - not to mention - and give you all credits. Please feel free to write me at richiehere @ hotmail . com. Good luck and secure programming!
Securing user enrollments in applications
What is User Registration?
User registration simply means introducing intended users to the software for the first time. User registration is typically a one-time operation. Post-user registration users start using the services of the software. User registration should be given more attention when designing your applications.
Why is User Registration Important?
User registration is important because it...
1. provides assurance that only bonafide users are added to the system.
2. provides accountability by reducing chances of backdoor entry into the system.
3. allows trust to be transferred from the software to the intended users of the software.
What kind of applications require User Registration?
Some examples of applications requiring User Registration are:
a) A customer-service portal for a telephone company
b) An online banking website for a bank
c) An extranet website hosted by a company
What security problems are caused due to poor User Registration?
Some problems associated with poor user registration are:
a) Introduction of ghost users in the system
b) Easy subversion of the user creation logistics
c) Confusing forensic paths which make it difficult to pin down hacking attempts to a process employed by the system
User registration consists of three distinct parts:
1. Create User - Creating users at the software console
2. Link User - Associate physical people with the created users
3. Transfer Control - Handing over initial credentials to the linked physical users.
User registration simply means introducing intended users to the software for the first time. User registration is typically a one-time operation. Post-user registration users start using the services of the software. User registration should be given more attention when designing your applications.
Why is User Registration Important?
User registration is important because it...
1. provides assurance that only bonafide users are added to the system.
2. provides accountability by reducing chances of backdoor entry into the system.
3. allows trust to be transferred from the software to the intended users of the software.
What kind of applications require User Registration?
Some examples of applications requiring User Registration are:
a) A customer-service portal for a telephone company
b) An online banking website for a bank
c) An extranet website hosted by a company
What security problems are caused due to poor User Registration?
Some problems associated with poor user registration are:
a) Introduction of ghost users in the system
b) Easy subversion of the user creation logistics
c) Confusing forensic paths which make it difficult to pin down hacking attempts to a process employed by the system
User registration consists of three distinct parts:
1. Create User - Creating users at the software console
2. Link User - Associate physical people with the created users
3. Transfer Control - Handing over initial credentials to the linked physical users.
Subscribe to:
Posts (Atom)